
A CHIPEK FORRADALMA
a System on a Chip (SoC) architektúra - II. rész
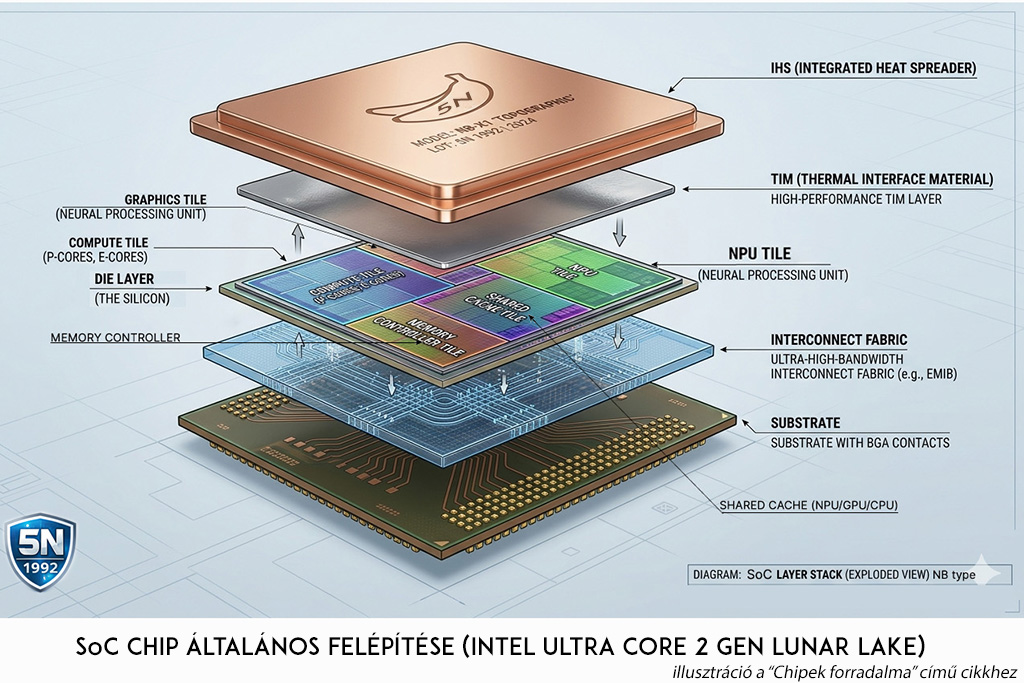

6. Gyártói architektúrák: Intel vs. Qualcomm evolúció
Alig pár éve még a Raptor Lake (Intel 13-14. generáció) volt a csúcs, és meg voltunk győződve róla, hogy a chipgyártás jövője örökre az Intel és az AMD kétpólusú világában marad. Ez az architektúra még egy olyan környezetben született, ahol az AI-gyorsítás a tervezőasztal sarkán gyűlő kupac alján sem szerepelt. A recept egyszerű volt: több mag, magasabb órajel, több áram. Ha valami lassú volt, „ráküldtek” még pár wattot, és ha AI-feladat jött, azt a CPU izomból, a GPU pedig nyers erővel próbálta letolni. Az eredményt mindannyian ismerjük: a ventilátor visít, az akkumulátor pedig előbb fogy el, minthogy elérnénk a konnektorig. Dünnyögtünk, szidtuk a gyártókat meg a „tervezett elavulás” oltárán feláldozott akkumulátorokat, hogy már semmi sem a régi (bezzeg a Holdra szállás...).
Aztán megérkezett a Qualcomm Snapdragon X Elite, és berúgta az ajtót. Ez volt az a pillanat, amikor az Intel rájött, hogy baj van. A Qualcomm nem a PC-k, hanem az okostelefonok világából jött, ahol minden egyes milliwattért meg kell küzdeni. A Snapdragon X Elite pedig nem csak „próbált” AI-képes lenni: eleve arra tervezték. Míg az Intel még mindig azt próbálta kitalálni, hova szorítson be egy AI-gyorsítót, a Qualcomm egy olyan monolitikus (egybeöntött) architektúrát tett le az asztalra, ami nevetségesen kevés energiából produkált brutális NPU-teljesítményt (45 TOPS). Ez a chip egyszerűen letolta az Intelt a pályáról, és megmutatta: a jövő laptopja nem egy kisméretű asztali gép, hanem egy óriási okostelefon agyával rendelkező munkaállomás.
* Lunar Lake TDP alapértelmezetten: 17W (PBP)/ 30W a turbo.
6.1 A Chiplet-iskola (Intel és AMD)
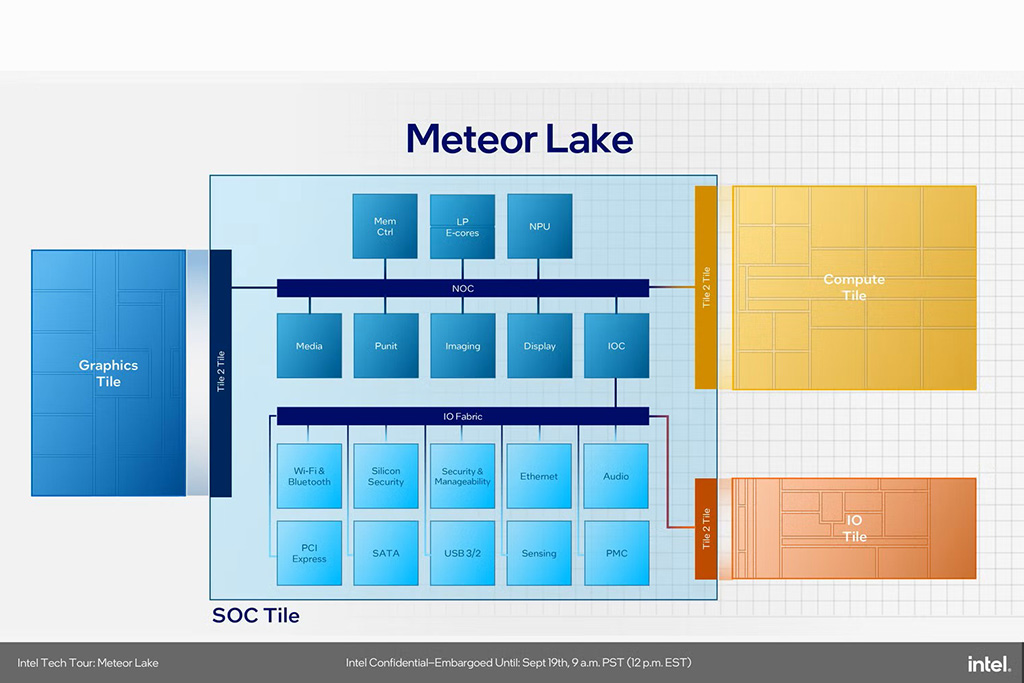
Az Intel nem nézhette tétlenül a trónfosztást. Első próbálkozásuk a 2023 végén debütált Meteor Lake család volt, ahol beraktak egy szerény NPU-t a régi struktúra mellé.
De mégis: a Meteor Lake volt az első „csempe” alapú Intel processzor, ahol az NPU még nem kapott dedikált tile-t – a SoC Tile részeként működött, elbújva a tranzisztor-rengetegben. Teljesítménye (11 TOPS) pedig még igen kevés volt a világmegváltáshoz.
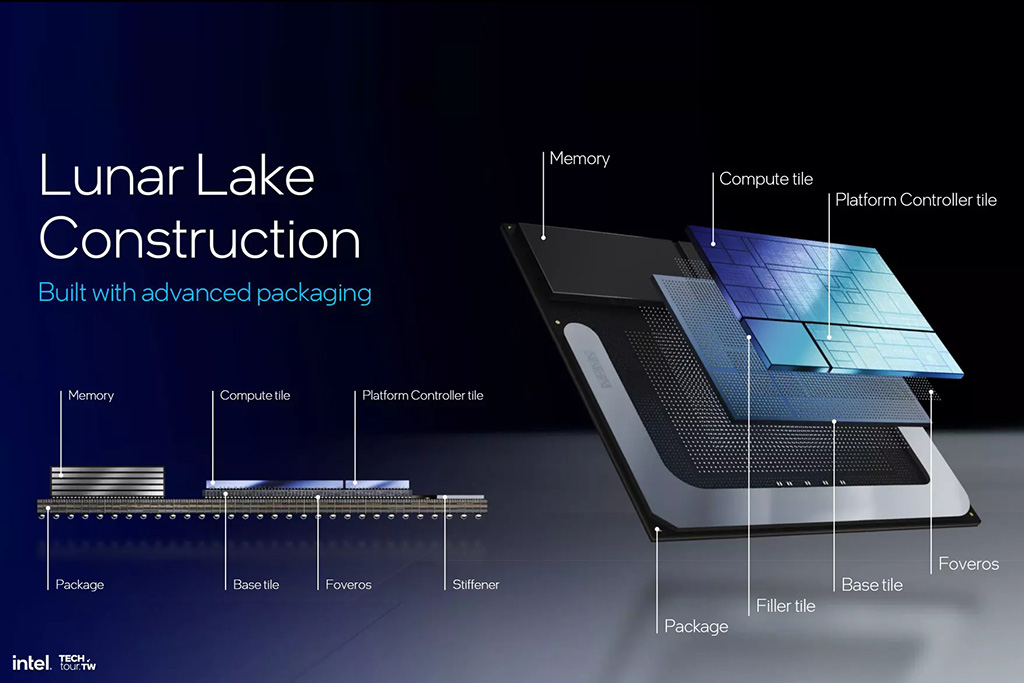
2024-ben a Qualcomm tarolt a hatékonysági teszteken, az Intelnek pedig „all-in” jelleggel mindent be kellett vetnie. Így született meg – alig 9 hónappal a Meteor Lake után – a 2024 szeptemberében debütáló Lunar Lake család (Core Ultra Series 2).
Ez a szokatlanul rövid fejlesztési ciklus is jól mutatja, mekkora volt a nyomás a Qualcomm és az Apple térnyerése miatt. A Lunar Lake-nél az Intel mérnökei elengedték a régi dogmákat, és alkalmazni kezdték azt, amit eddig csak a mobilgyártók mertek. Ha igazán mélyre ásunk a Lunar Lake (Core Ultra Series 2) felépítésében, látható, hogy az Intel nem csupán lemásolta a mobilvilág megoldásait, hanem egy minden elemében AI-optimalizált erőművet hozott létre.
- Dedikált AI Powerhouse: Itt az NPU már nem egy elrejtett kiegészítő, hanem egy brutális, központi elem (~48 TOPS). Fizikailag is hangsúlyosabb területet kapott a szilíciumon: ha ránézünk a chip metszetére, az NPU területe "ordít" a grafikonról, jelezve, hogy a tervezés során ez élvezett prioritást.
- A GPU titkos fegyvere –A Lunar Lake Xe2-es grafikus motorja már dedikált AI-gyorsítókat tartalmaz a GPU-n belül is. Ez a gyakorlatban azt jelenti, hogy amikor az NPU és a GPU összeáll, egy ultravékony laptop is képes arra a helyi AI-teljesítményre, amihez korábban egy asztali munkaállomás nyers ereje (és áramfelvétele) kellett.
- MoP (Memory on Package): Ahogy a felépítésnél láttuk, a RAM közvetlenül a processzor tokjára került. Ez a fizikai közelség radikálisan csökkenti a késleltetést és az energiaigényt. Ezért van az, hogy a Lunar Lake ránézésre sokkal inkább emlékeztet egy Apple M-szériás chipre vagy egy csúcskategóriás telefonos SoC-ra, mint egy hagyományos PC-processzorra.
- Foveros technológia: A chiplet-legót olyan szintre emelték, ahol a különböző rétegek egymáson és egymás mellett dolgoznak.
A Foveros 3D-váz
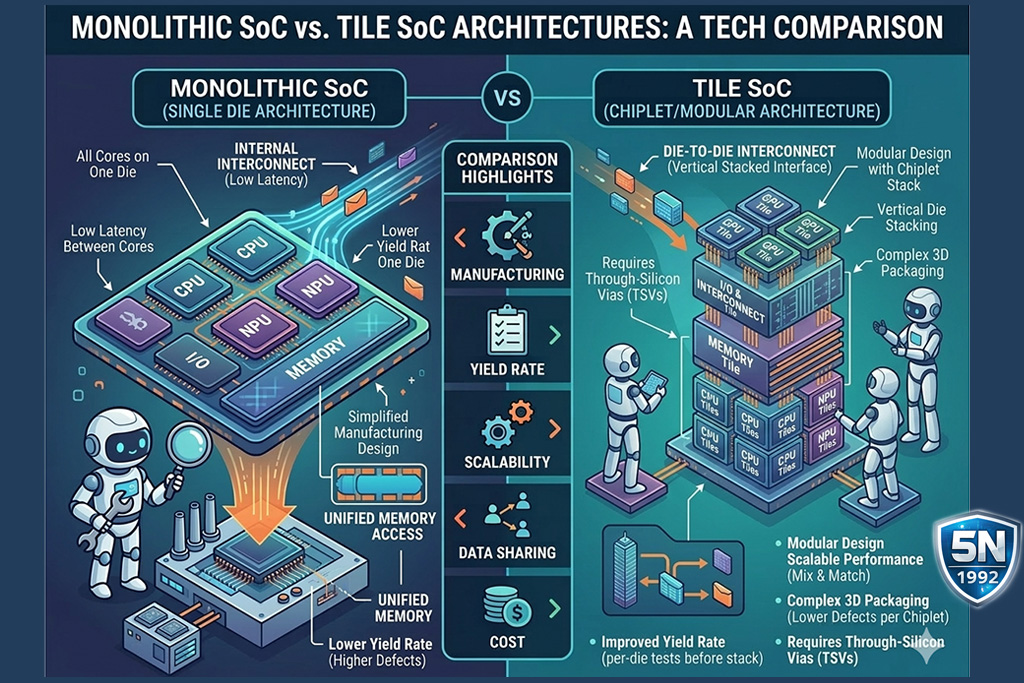
A Lunar Lake lenyűgöző hatékonysága mögött az Intel Foveros (3D Packaging) technológiája áll. Ha a hagyományos chipgyártás egy egyszintes családi ház, akkor a Foveros egy felhőkarcoló, ahol a specializált AI-egységek, a processzormagok és a memória egyetlen, rendkívül sűrű csomagban dolgoznak együtt. Ahelyett, hogy egyetlen óriási és drága szilíciumlapkára zsúfolnának mindent (mint a Raptor Lake-nél), a processzort különálló Tile-okra (lapkákra) bontották, ahol kisebb, specializált egységek jutnak a processzormagoknak, a grafikának és az NPU-nak. Ezeket pedig egy közös alapra, az úgynevezett Interposer-re ültették rá őket, melyeket egy szupergyors, rétegelt alaplemezen (base tile / interconnect) keresztül fogják össze.
Miért ez a kulcs az AI-korszakhoz?
- Függőleges adatlift (TSV): Míg a régi chipeknél az adatoknak hatalmas kerülőket kellett tenniük az alaplapon, itt függőleges lifteken (áramkörökön) közlekednek a „felhőkarcoló” rétegei között. Ez minimális késleltetést és maximális sávszélességet biztosít az NPU-nak – az adat nem „utazik”, hanem „ott van”.
- Hibrid gyártás és gazdaságosság: A Foveros lehetővé teszi, hogy a számítási egységet (Compute Tile) a legdrágább 3nm-es eljárással, míg a kevésbé kritikus elemeket olcsóbb, megbízhatóbb technológiával készítsék el, majd a végén „összelegózzák” őket. Ez komoly fegyvertény a Qualcomm monolitikus felépítésével szemben, mert rugalmasabb és költséghatékonyabb gyártást tesz lehetővé.
- A moduláris Tile felépítés előnye, hogy ha a GPU Tile meghibásodik, csak azt dobják ki, a többi használható. Ez a kihozatali arány szempontjából óriási előny, és hosszú távon olcsóbb gyártást tesz lehetővé.
- Intelligens hőmenedzsment: Mivel a lapkák egymáson és egymás mellett vannak, az Intel mérnökei sakkozhattak az elhelyezéssel. A forró CPU-magok és a hatékony NPU külön „szigeten” laknak, így az NPU nem melegíti feleslegesen a processzort, a hőelvezetés pedig közvetlenebb a felső rétegek felé.
- A jövő záloga: Ez a moduláris felépítés azt jelenti, hogy a következő generációnál az Intel megteheti, hogy csak az NPU-lapkát cseréli nagyobbra vagy erősebbre, anélkül, hogy az egész processzort az alapoktól újra kellene terveznie.
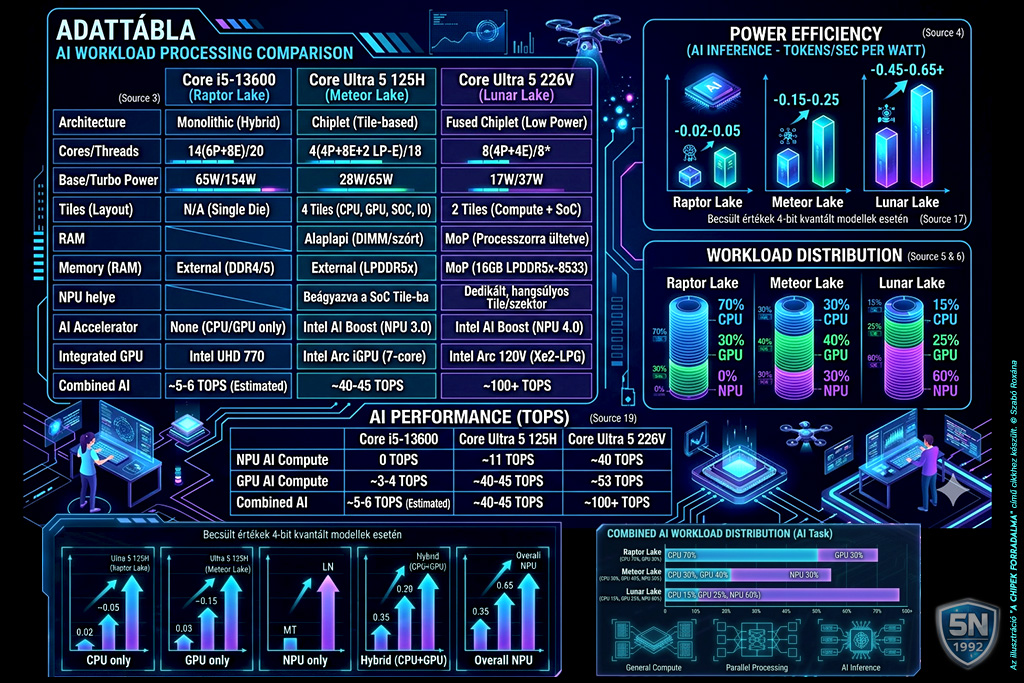
| Jellemző | Meteor Lake (Core Ultra 1. gen) | Lunar Lake (Core Ultra 2. gen) |
| NPU helye | Beágyazva a SoC Tile-ba | Dedikált, hangsúlyos Tile/szektor |
| RAM | Alaplapi (DIMM/szórt) | MoP (Processzorra ültetve) |
| AI Teljesítmény | Belépő szint (~11 TOPS) | Professzionális szint (~48 TOPS) |
| Filozófia | Hagyományos PC + AI modul | Mobil-architektúra PC méretben |
| NPU Teljesítmény | ~11 TOPS | ~48 TOPS |
| Összesített AI (CPU+GPU+NPU) | ~34 TOPS | ~120 TOPS |
| Áramfelvétel (TDP) | ~15-28W | ~8-30W (feladatfüggő) |
A Lunar Lake az első olyan Intel chip, ami végre „megtanult telefonul”. Nem csak az ereje van meg, de megvan benne az a mobilról ismerős intelligens energiagazdálkodás is, ami lehetővé teszi, hogy egy Windows-os laptop is kibírjon egy egész napot AI-feladatok mellett, csendben, ventilátorzaj nélkül.
6.2 A Monolitikus iskola (Qualcomm és Apple)
| Széria / Modell | Korszak | NPU Teljesítmény (TOPS) | Fő jellemző |
| 8 Gen 2 (Mobile) | 2022/23 | ~26 TOPS (összesített) | Itt vált az AI a fotózás alapjává. |
| 8 Gen 3 (Mobile) | 2024 | ~45 TOPS (összesített) | Az első, ami képes volt 10B+ paraméteres LLM-et futtatni mobilon. |
| Snapdragon X Plus | 2024 (PC) | 45 TOPS (Csak az NPU) | A belépő szintű Windows-on-ARM Copilot+ PC alapja. |
| Snapdragon X Elite | 2024 (PC) | 45 TOPS (Csak az NPU) | A nagyágyú. 12 Oryon mag, brutális hatékonyság. |
A Qualcomm (Snapdragon X Elite) és az Apple (M-széria) a mobilvilág örökségét emelte át a laptopokba: egyetlen monolitikus die-ra integrál mindent (mint a telefonokban). Ez kevesebb hőt termel, de nehezebb és drágább gyártani a nagyméretű, hibátlan szilíciumlapkát. Ez a monolitikus felépítés.
- A logika: Itt nincs legózás. Minden – a CPU, a GPU és az NPU is – egyetlen, folytonos szilíciumtömbön kap helyet. Nincsenek illesztések, nincsenek különálló „csempék” a tokozáson belül.
- A mérnöki érv: Mivel nincsenek fizikai határok a chipek között, az adatoknak nem kell „hidakon” átkelniük. Ez eredményezi azt a rendkívüli energiahatékonyságot és alacsony késleltetést, ami miatt ezek a rendszerek AI-feladatok alatt is meglepően hűvösek maradnak, az akkumulátoruk pedig akkor is bírja a munkanap végéig, ha helyben futtatunk nyelvi modelleket.
- AI-hatás: A monolit kialakítás miatt az NPU közvetlenebbül fér hozzá az erőforrások-hoz, de emiatt a rendszer nem skálázható olyan rugalmasan, mint a tile-alapú társai.
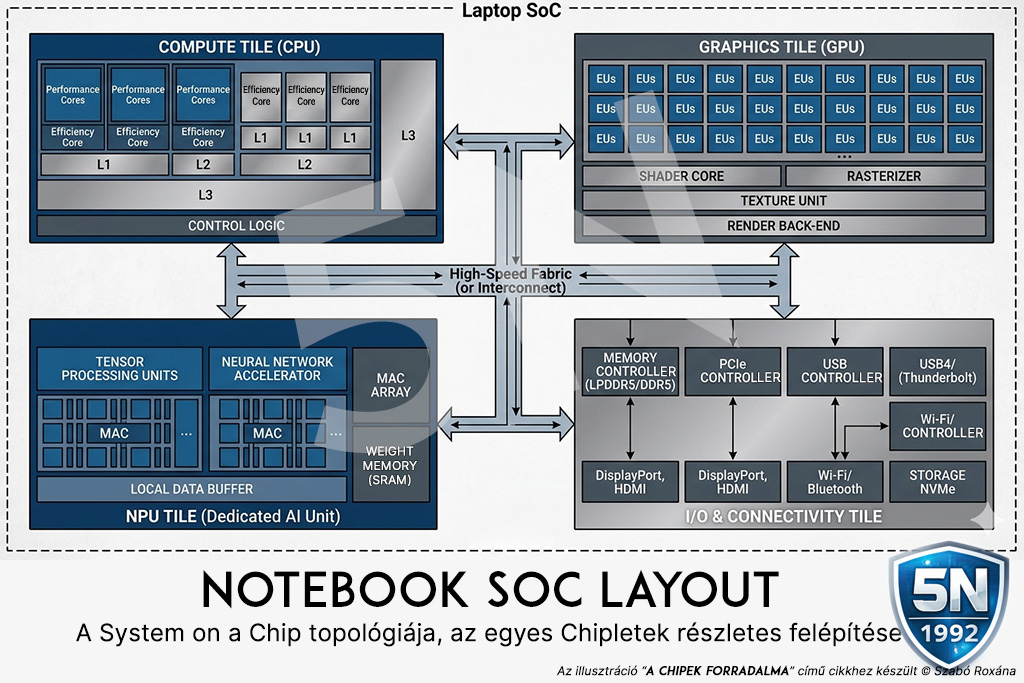
7.1. A processzor (SoC) felépítése és a chipletek funkciói:
- Compute Tile (P-Cores & E-Cores): Ez a klasszikus CPU, a soros feladatok felelőse. A P-magok a nehéz számításokért, az E-magok az alacsony prioritású háttérfolyamatokért felelnek, hogy a rendszer alapjárata ne egyen feleslegesen áramot.
- Graphics Tile (Xe GPU): A beépített videóvezérlő, amely a párhuzamos AI-feladatokat (pl. képalkotás, videós effektek) gyorsítja.
- AI & NPU Tile: A dedikált AI-motor. Kifejezetten mátrixszorzásra és neurális hálók futtatására van optimalizálva (INT8 és FP16 műveletek), minimális energiafelvétel mellett.
- I/O & Connectivity Tile: A külvilággal való kommunikáció (PCIe 4.0/5.0, USB 4) kapuja. Kieg: PCIe 6.0: jelenleg csak szerver környezetben elérhető
- Memory Controller Tile: A memória közvetlen eléréséért felelős egység.
7.2. A CPU mint karmester (I/O Orchestráció)
A modern AI-alaplapokon a CPU szerepe alapvetően megváltozott: már nem ő végzi a nehéz számítási munkát, hanem karmesterként koordinálja az adatáramlást. Míg az NPU és a GPU dolgozik, a CPU feladata a „szállítószalag” (PCIe sávok) menedzselése, hogy a hálózati forgalom (NIC) vagy a tárhely (NVMe) ne váljon szűk keresztmetszetté.
- Vezérlés és Szállítás: Az NPU nem önmagától kezd el dolgozni. A CPU küldi neki az utasítást ("Az adatokat a RAM-ban a 0xAF12 címtől találod").
- Önkiszolgáló adatelérés (DMA): Amint az NPU megkapta a parancsot, a fizikai adatmozgatást már nem a CPU végzi. Az NPU a saját DMA (Direct Memory Access) vezérlőjével közvetlenül a RAM-ból vagy a közös gyorsítótárból (L3 Cache) húzza be a szükséges modellt. Ha ezt is a CPU-nak kellene „átlapátolnia”, a processzor 100%-on pörögne csak az adatmozgatás miatt, és a rendszer megállna.
7.3. I/O Fabric: Búcsú a múlttól
A modern AI-platformoknál végleg búcsút intünk a régi Northbridge/Southbridge felosztásnak. Az I/O vezérlés közvetlenül az SoC (System-on-Chip) részévé vált. Ez a közvetlen integráció biztosítja, hogy a hálózati kártyák és a villámgyors NVMe tárolók adatfolyama ne terhelje az általános célú buszokat, hanem akadálytalanul jusson el az AI-gyorsítókhoz.
ÖSSZEFOGLALVA:
Az AI-korszak architektúrái egy teljesen új gondolkodásmódot tükröznek: a specializáció és a szimbiózis lett a kulcs. A CPU, GPU és NPU hármasa egy szinergens ökoszisztémát alkot, ahol az együttműködés révén érnek el olyan hatékonyságot, amire külön-külön egyikük sem lenne képes.
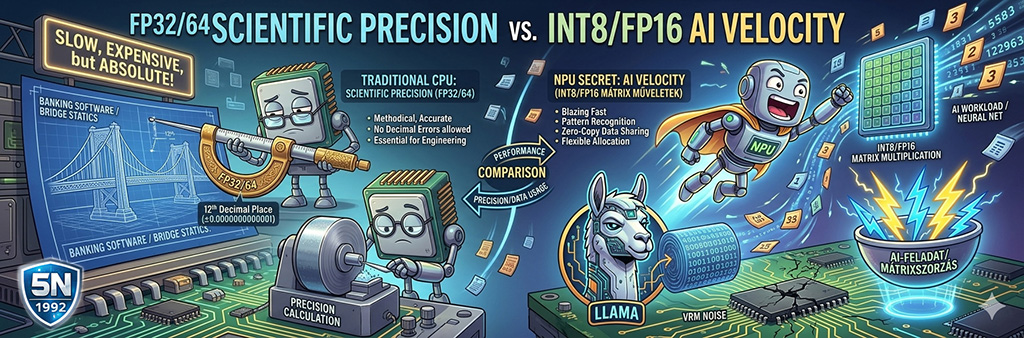
Az NPU nem csak AI-kellék, hanem általános matematikai gyorsító
Ne gondoljuk, hogy az NPU egyfajta szoftveres extra, amit csak akkor használunk, ha chatbotokkal beszélgetünk. Ahogy a GPU is kitört a videójátékok börtönéből, és ma már a kezelőfelületek simaságáért vagy a videókódolásért felel, az NPU is ugyanerre az útra fog lépni.
Az architektúra már most is olyan dolgokat végez a háttérben, amiket nem feltétlenül hívnánk mesterséges intelligenciának. Az NPU használata az erre képes eszközökben nem egy esetleges opció (mint a fűthető ülés az autóban). Ha az autós hasonlatnál akarunk maradni, akkor inkább sebváltóhoz hasonlítanám: míg a CPU-val egyesben, magas fordulatszámon, alacsony hatásfokon és nagy fogyasztással dübörög a rendszer, addig az NPU-val felvált ötödikbe: csendesebb, hűvösebb és sokkal hatékonyabb lesz.
Hiszen, gondoljuk bele: rengeteg olyan hétköznapi feladatunk van, ami valójában nem igényel intelligenciát, csak tömeges, repetitív mátrixműveleteket (adatok tömörítése, titkosítási algoritmusok, képélesítés). Eddig ezeket a CPU-val végeztettük el.
Az NPU megjelenésével viszont ezek a feladatok átkerülnek egy olyan egységre, ami tizedannyi energiából végzi el ugyanazt, hiszen az NPU architektúrája egy "futószalag". Arra tervezték, hogy elképesztő mennyiségű, egyszerű matematikai műveletet (szorzást és összeadást) végezzen el párhuzamosan. Minden olyan feladat, ami nagy adathalmazok hasonló átalakításáról szól, profitál belőle. Így, ha egy komplex pénzügyi szimulációt vagy titkosítási algoritmust kap feladatként, ami mátrix-alapú, akkor is pillanatok alatt ledarálja és drasztikusan kevesebb energiát fogyaszt el közben.
Az NPU kihasználásának legnagyobb akadálya jelenleg nem a hardver, hanem az, hogy a programozóknak meg kell tanulniuk használni ezeket a képességeket és "szólni" hozzá. De hamarosan érkeznek azok a tömörítők, fájlrendszer-kezelők és böngészőmotorok, amik csak a puszta matematikai hatékonysága miatt fogják használni az NPU-t.
Nézzük meg, mi történik a "gépházban", ha nem AI-ról beszélünk (az NPU szerepe hagyományos környezetben)
- Tehermentesítés (Offloading): Az NPU leveszi a CPU válláról azt a monoton matematikai „zajt”, ami eddig feleslegesen emésztette az energiát és termelte a hőt.
- Jelfeldolgozás (DSP): jelfeldolgozási algoritmusok gyorsítása: emiatt a gép sokkal hatékonyabban végzi el a FFT (Gyors Fourier-transzformáció) jellegű számításokat, mint egy általános CPU-val.
- Kép- és videófeldolgozás (nem AI alapon): A színek korrekciója, a zajszűrés vagy a kódolás bizonyos szakaszai mátrixműveletek. Ha a szoftverfejlesztő megírja a támogatást, az NPU ezeket energiafelvétel szempontjából fillérekből oldja meg.
Zárásként:
Az NPU nem csak egy AI segédlet, hanem általános hatásfok javító: gyorsabb, egyszerűbb munkavégzést jelent, tizedannyi energia felhasználásával. Ez az irány a következő években az irodai és hordozható eszközökben is alapértelmezetté válik. A modern hardverek „boszorkány-tesztje” ma már nem arról szól, hogy lebeg-e a vízen – azaz, hogy képes-e pusztán nyers erőből futtatni egy kódot. A valódi próbatétel az, hogy a gépünk mennyire „okosan” gazdálkodik az energiával: képes-e zajtalanul és halkan kiszolgálni minket, miközben az akkumulátor minden egyes milliwattjából a maximumot hozza ki.
Köszönöm mindazok érdeklődését és figyelmét, akik eljutottak idáig. Együtt éltük át a chipek forradalmát!
©Szabó Roxána-5N Kft 2026

ELŐZMÉNY CIKK: I. rész: A CHIPEK FORRRADALMA >>>>>>
Az AI hatása az architektúrára, UMA és parcellázott SoC megjelenése, NPU kihívás, Interconnect, tiles, Szent Háromság: CPU-NPU-GPU, Adatformátumok: FP64/32 és FP16/INT8/4 szerepe, Kvantálás, Infrastruktúra követelmények, VRM és PSU, Memória és PCB szám, Hűtés, BIOS, Specifikus eltérések: MoP és diszkrét DDR5 (DIMM)
EZ A CIKK (FOLYTATÁS): A CHIPEK FORRRADALMA: II. rész >>>>>>
Gyártói architektúrák: Intel vs. Qualcomm evolúció, Chiplet iskola, Forevos váz, Monilitikus die, modern SoC felépítése és anatómiája, Funkciók, SoC Layout, NPU csak AI kellék?
TRANSPARENCY DISCLOSURE – AI Act compliance
Ez a tartalom a mesterséges intelligencia etikus és transzparens támogatásával készült, az EU AI Act irányelveivel összhangban:
Szerző és szerkesztő: Szabó Roxána © 5N Kft
AI-támogatás:
▸ Háttér információk, anyaggyűjtés, tanácsadás: Gemini (Google LLC)
▸ Tartalmi és stilisztikai ellenőrzés: Claude AI (Anthropic)
▸ Képgenerálás: Gemini 3 Flash (Google LLC)
