
A CHIPEK FORRADALMA
a System on a Chip (SoC) architektúra - I. rész

1. Az AI hatása az architektúrára
A mesterséges intelligencia fejlesztése és kutatása évtizedekig stagnált. Ez volt az AI Winter. Nem azért, mert nem volt rá igény, hanem mert egyszerűen nem volt alá „vas”. A fagyos mozdulatlanságot végül egy váratlan irányból jövő áttörés hozta el: a gaming éra videójátékainak egyre őrültebb grafikai igénye életre hívta azokat a GPU-architektúrákat, amikről kiderült, hogy pont azt tudják, amire a neurális hálózatoknak is szükségük van: brutális mennyiségű párhuzamos számítást gyorsan és olcsón. Ezek tették lehetővé a hálózatok tanítását és futtatását, áttörve a falat az AI előtt.
A napjainkban zajló tech-robbanáshoz foghatót az okostelefonok megjelenésekor láttunk utoljára, csak nem ebben a léptékben. A mobiltelefonos párhuzam nem véletlen: a mobilgyártók (Apple a Neural Engine-nel, a Qualcomm a Hexagon processzorral) már 2017-ben rájöttek, hogy a CPU túl sokat fogyaszt a képfeldolgozáshoz (HDR, portré), így bevetették az NPU-t. Mivel a telefonokban nincs hely alaplapi slotoknak vagy óriási hűtőbordáknak, a mobil NPU-k még agresszívebb Power Gating-et használnak, mint a PC-sek: az NPU „parcellája” fizikailag lekapcsolódik az áramról, hogy ne merítse az akkumulátort.
A jelenlegi chipek pedig pont ezt az architekturális integrációt emelik át a PC-s környezetbe. A gamer kultúra és az okostelefonok fejlődése katalizátorként hatottak az informatikára; mert a továbblépésnek itt már hardveres korlátai voltak. A SoC architektúra beemelése a munkaállomások infrastruktúrájába radikális mérnöki válasz volt a fizikai korlátokra. A váltás kreativitása pedig önmagában is lenyűgöző: az Unified Memory Architecture és a parcellázott SoC már bizonyított, fizikailag jól behatárolható és finomhangolt energiagazdálkodású terület. Ezt a technológiai eleganciát ültetik most át a Windows környezetbe.
Ezért az AI hatását most nem jogi, etikai vagy disztópikus szempontból közelítjük. Én az ehhez kapcsolódó mérnöki teljesítmény előtt szeretnék tisztelegni, így ebben a cikkben a szemünk előtt zajló technológiai átalakulást vesszük nagyító alá.
Mert lehet rajongani sok mindenért, de ahol a mérnöki kreativitás és teljesítmény az architektúraváltás ilyen fokú eleganciáját hozza el, az már a hatékonyság esztétikája.
2. Az NPU kihívás
A jelenlegi hagyományos architektúrák nehezen kezelik az AI-használat kihívásait: megnövekedett számítási igény, hirtelen energiatüskék és nagyon magas memóriaigény jellemzik a folyamatot.
A legegyszerűbb válasz a memória-éhségre a HBM (High Bandwidth Memory) használata lett volna. De ennek a technológiának a helyigénye és hőtermelése szerverekre és adatközpontokra méretezett: egyszerűen összeegyeztethetetlen a vékony készülékházakkal. Ezért a hordozható eszközökbe integrált AI-gyorsítás (NPU) alapjaiban tér el az adatközponti megoldásoktól. A kulcs itt nem a terabájtos sávszélesség, hanem az egységnyi wattra jutó számítási teljesítmény (TOPS/Watt).
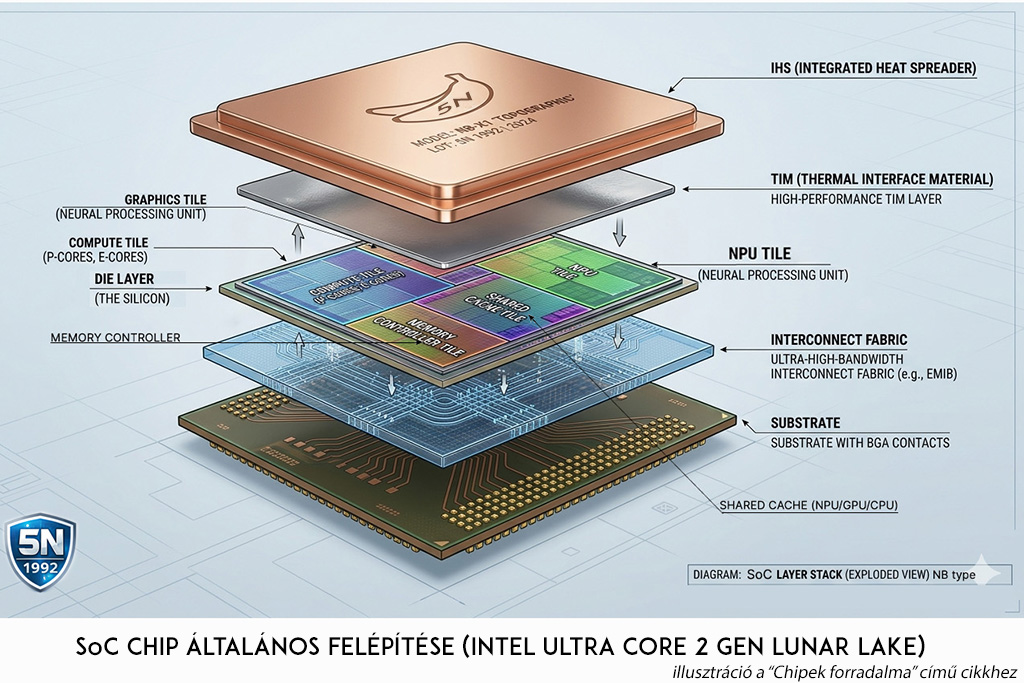
Ennek megoldására született meg az AI-használatot támogató SoC (System on a Chip) architektúra, ami három eltérő karakterisztikájú „motor” szinergiája: együtt adják azt a hatékonyságot és stabilitást, ami egy modern irodai vagy szerver környezetben elvárható. Ez teszi lehetővé, hogy az NPU átvegye a háttérben futó AI-feladatokat (pl. zajszűrés, prediktív szövegírás, háttérelmosás videóhívásnál), így a CPU és GPU szabad marad a valódi munkára – legyen az virtualizáció, mentéskezelés vagy ügyviteli rendszerek –, és az akkumulátor sem merül le 20 perc alatt. A SoC lényege a szegmentáció: több kisebb, specializált chiplet, amiket egy szupergyors belső adatbusz (interconnect) köt össze.

A három motor (A "Szent Háromság")
| Motor | Szerep az AI-ban | Memória elérés | Architektúra |
| CPU | OS, logika, vezérlés. Karmester, de az AI-számításokban lassú. Magas latency. | LPDDR5x (Shared) | Soros (Scalar) |
| GPU | Masszív párhuzamos feldolgozás, komplex AI-grafika, nagy mátrixok. | LPDDR5x (Shared) | Párhuzamos (Vector) |
| NPU | Neurális hálók matematikájára és mátrixműveletek gyorsítására optimalizálva.* | LPDDR5x (Shared) | Alacsony bitmélységű (Tensor) |
*Ugyanazt az AI-feladatot töredék energiával oldja meg, mint a CPU és/vagy a GPU.
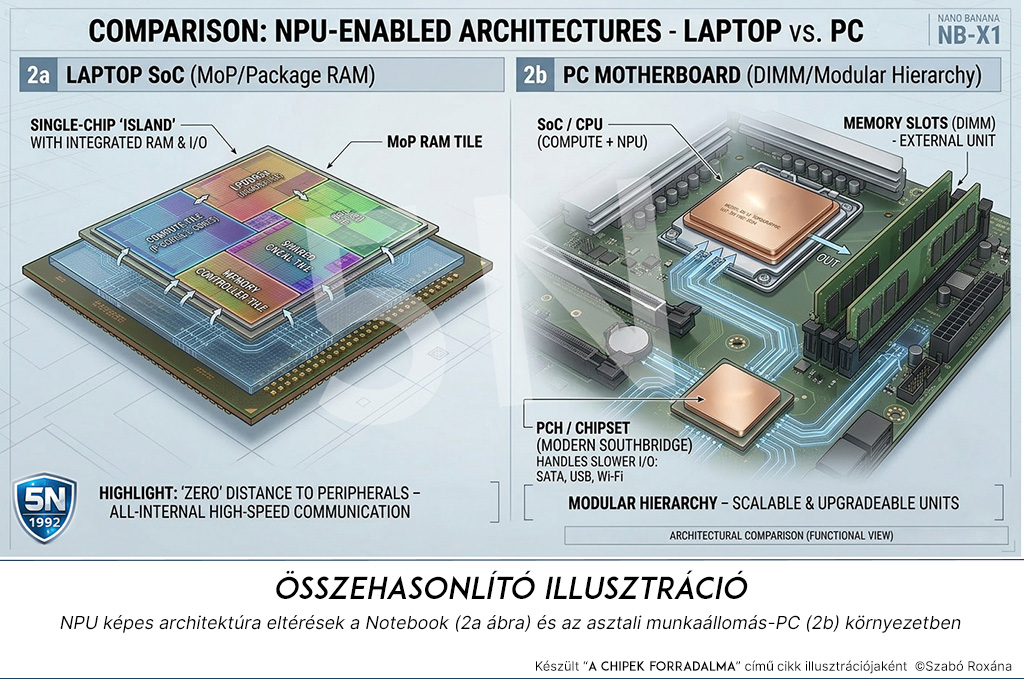
Ebben az architektúrában a hatékonyságnövekedést a shared LPDDR5x memória és a dedikált NPU szoros integrációja biztosítja. Fontos különbség, hogy míg notebookoknál a memória már nem az alaplapon, hanem a processzor tokozásán belül (on-package/MoM) helyezkedik el, addig az asztali PC-knél megmarad a moduláris (DIMM foglalatos) felépítés. Az on-package megoldás a fizikai távolság minimalizálásával drasztikusan javítja az adatáramlást a három motor között.
A technológia hátránya, hogy a DDR5/LPDDR5x memória sávszélessége (kb. 60-140 GB/s) fényévekre van a szerveroldali HBM-től (a legújabb HBM3E esetén 3000+ GB/s, korábbi generációknál 900-2000 GB/s), így a jelenlegi fogyasztói NPU-k inkább kisebb, lokális modellek kiszolgálására alkalmasak.
Az igazi nagy nyelvi modelleknek (Gemini, Claude, ChatGPT) továbbra is elengedhe-tetlen a HBM sávszéles-sége, hogy „elszaladgáljanak” rajta. Emiatt a SoC-s, LPDDR5x-alapú megoldás szerver vagy adatközponti környezetben még nem releváns, de a távolság mindkét irányból csökken: az LLM-ek oldaláról az 1 bites kvantálás (BitNet) és a könnyűsúlyú modellek (Llama) egyre kevesebb erőforrást igényelnek, hardver oldalon pedig az SoC-k memória-integrációja és NPU-teljesítménye generációról generációra nő. A kettő metszéspontja az egyik legaktívabb fejlesztési terület.

3. Adatformátum CPU vs NPU
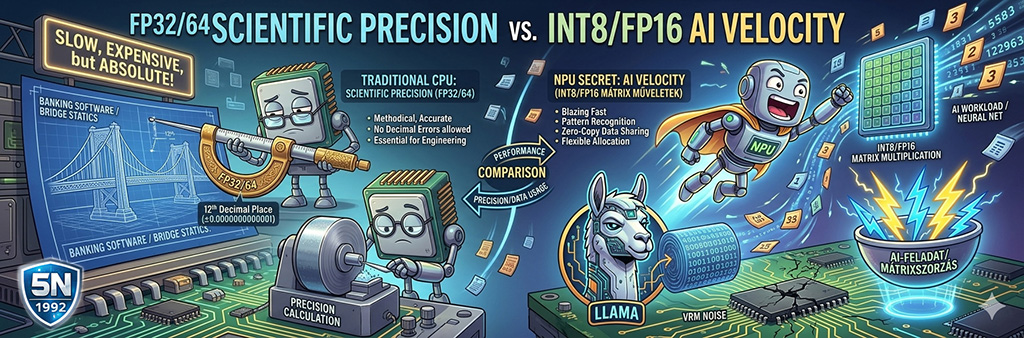
Ahhoz, hogy az NPU valódi értelmét megértsük, tegyünk egy rövid kitérőt a bitek világába. A processzorok (CPU) eredeti küldetése a tudományos és mérnöki precizitás kiszolgálása volt – ott, ahol egy elvétett tizedesjegy katasztrófát okoz. Ezért a CPU 32 vagy 64 biten "rágódik" minden számon. Azonban ahogy a számítástechnika átszőtte a hétköznapokat, a feladatok jellege radikálisan eltolódott.
A modern digitális folyamatok többségéhez – legyen szó képfeldolgozásról, mintázat felismerésről vagy a közösségi média kezeléséről – nincs szükség patikamérlegre és tudományos mélységre. Valójában a 64 bites CPU túlméretezett mindenre, ami csak „érzékelni” vagy „megjeleníteni” akar, nem pedig atompályákat számolni. Ezekhez az egyszerű digitális feladatokhoz a sebesség és az energiahatékonyság sokkal fontosabb, mint a mikroszkopikus pontosság. Ezért a hagyományos CPU-k 64 bites precizitása ezen a szinten már olyan energiapazarló fényűzés, mintha egy Chanel kosztümben és Prada magassarkúban indulnánk el a sarki közértbe, hogy onnan két nehéz cekkerrel a kezünkben egyensúlyozzunk haza a flaszteren.
Az INT8/ FP16 adatformátum jelentősége
FP64/32/16 és INT8: ezek a számok azt jelzik, hogy hány biten tárol a processzor egy-egy számértéket a számítás során. Minél több a bit, annál pontosabb a szám, de annál több memóriát és energiát is fogyaszt. Az NPU egység ezeket használja:
- INT8 (8-bit Integer): Egész számok. Nagyon kevés helyet foglalnak, és brutális sebességgel lehet velük számolni. Az AI-modellek „butított”, de gyorsított változatai (kvantálás után) ebben futnak.
- FP16 (16-bit Floating Point): Lebegőpontos számok. Ez egyfajta arany középút: elég pontos a legtöbb AI-feladathoz (pl. képalkotás), de sokkal hatékonyabb, mint a hagyományos tudományos számításoknál használt 32 vagy 64 bites formátumok.
A neurális hálózatok működése több milliárd apró szorzásból és összeadásból áll (MAC - Multiply-Accumulate műveletek), amiket az AI-ok hatalmas táblázatokba (mátrixokba) rendeznek. A „mátrixszorzás” maga a matematikai művelet, amit el kell végezni, az INT8 és FP16 pedig az az "adat-nyersanyag", amin ezt a műveletet végrehajtják.
Az NPU titka az, hogy a processzorát ezekhez a "pontatlanabb", de villámgyors INT8/FP16 mátrixműveletekhez huzalozták be, mert itt nem egyetlen szám abszolút értéke számít, hanem a súlyok és kapcsolatok hálózata. Ahhoz, hogy egy AI felismerjen egy kutyát a képen, ez bőven elég. Ha egy neurális hálóban 100 millió paraméter szavaz arról, hogy a képen egy kutya van-e, nem oszt, nem szoroz, hogy az egyik paraméter értéke 0,756432 vagy csak simán 0,7. A tömegszerűség (a mátrix mérete) kijavítja az egyedi számok pontatlanságát. Így a hardver (NPU) ugyanannyi energiából nem 10, hanem 1000 műveletet tud elvégezni. Ezért tud az NPU 48 TOPS (billió művelet per másodperc) teljesítményt leadni anélkül, hogy megolvasztaná a laptopot. Ennek az az ára, hogy a modern AI-hardver az "elég jó" pontosságot választja a "tökéletes" helyett, mert a kontextus (a mátrix többi eleme) ellensúlyozza a hibát. Viszont ha túl sok "bitet" vágunk le a sebesség oltárán, a modell elkezdi elveszíteni a valóságot.
Miért? (a hallucináció és a pontosság kapcsolata)
- A kvantálási hiba (A "butítás"): Amikor egy hatalmas AI-modellt lebutítunk INT8-ra, hogy elférjen a laptopon és gyors legyen, információt veszítünk. A korábbi generációs modelleket még FP32-ben tanították — ma már a nagy nyelvi modellek (GPT, Claude, Llama, Gemini) eleve FP16-ban vagy BF16-ban készülnek, ami önmagában is egy jelentős hatékonysági ugrás. De még ebből a „féláron" tárolt tudásból is tovább „faragunk” az INT8 kvantálással. Amikor a processzor INT8-on dolgozik, egy-egy számértéket mindössze 8 biten tárol. Olyan ez, mintha egy nagyfelbontású (nyers) fotót agyontömörített JPEG-ként kellene elmenteni. A lényeg látszik, de a részletek elmosódnak. Ez okozhatja a bizonytalanságot a válaszokban.
- A "valószínűségi" természet: Mivel az egész rendszer valószínűségekre (mátrixszorzásokra) épül, az AI sosem "tudja" a választ, csak "kiszámolja a legvalószínűbb következőt". Ha a modell a gyorsítás (kevesebb bit) miatt elveszíti a finom összefüggéseket, könnyebben csúszik át egy olyan valószínűségi ágra, ami hülyeség (Mintha műholdképről néznénk egy sok ezer km hosszú csővezetéket) – és íme: a hallucináció.
A mérnöki feladat itt nem csak abból áll, hogy a modellt megfelelő mennyiségű, minőségű, friss és diszkriminációmentes adaton tanítsák be (bias: torzítás elkerülése), hogy ezekhez megfelelő súlyokat (weights: a neurális háló „emlékei”) rendeljenek, hanem az is része, hogy megtalálják a kvantálás („butítás”) optimális állapotát, ahol a modell még megfelelő élességgel működik, használható sebességen.
4. Az NPU-biztos infrastruktúra: Alaplap és tápellátás
A dobozokon díszelgő „AI PC” matricák jelen pillanatban a marketing-osztályok stratégiai játszóterét jelentik. Kis túlzással: ha a processzor belemegy a foglalatba, akkor boszorkány... AI. A valódi különbséget ennél sokkal összetettebb paraméterek határozzák meg, a lényeg a hűtőbordák alatt és a PCB rétegeiben rejlik. Bár az NPU nem igényel külön csatlakozót, de megfelelő alaplapi infrastruktúra nélkül maximum csak drága papírnehezékként vehetjük hasznát.
A.) Power Delivery: A VRM helyzet
Az NPU-k speciális „étvággyal” rendelkeznek: dinamikus „bursty workload” jellemzi őket. Egy AI-feladat elindításakor az egység nanoszekundumok alatt ugrik alvó állapotból maximum terhelésre. A nagy áramtüskék kezeléséhez masszívabb VRM és induktorok kellenek. Ha a feszültségszabályozás (VRM) „zajos” vagy lassú, az NPU számítási hibákat véthet a mátrixszorzásoknál, vagy egyszerűen instabillá válik.
A modern rendszerekben ezért kétlépcsős szabályozás működik:
- Külső VRM: Az alaplapi tekercsek és kondenzátorok a tápegység 12V-ját alakítják át kb. 1.0V – 1.8V szintre. Ha itt nincs elég „power delivery” kapacitás, a rendszer lassításra (throttling) kényszerül, vagy összeomlik.
- Belső VRM (FIVR): A SoC saját szabályozói finomhangolják tovább a feszültséget (pl. 1.05V-ról 0.85V-ra) az egyes Tile-ok (NPU, GPU) számára.
Egyszerűbb lenne a VRM elhelyezése csak a SoC-n belül? Igen. A kétlépcsős megoldás oka, hogy a jelenlegi technológia a feszültségátalakítás hőveszteségét nem tudja a chipen belül kezelni: a SoC simán leolvadna. Vagy akkora tekercsek és kondenzátorok kellenének hozzá, amik nem férnek el a szilíciumon. Ezért a „piszkos munkát” ki kell tolni az alaplapra, ahol a masszív hűtőbordák elvezetik a hő nagyját, és csak a finomhangolás marad a belső VRM-re.

Miért van ekkora jelentősége a VRM-nek az NPU esetében?
Bár a modern alaplapok feszültségszabályozó körei (VRM) és a processzorok belső szűrői (LDO - Low Dropout Regulators) sokat fejlődtek, a fizika határait nem tudják átlépni. Ha a tápegység (PSU) nem kap tiszta áramot, a rajta átjutó nagyfrekvenciás zajt a VRM-nek kellene kiszűrnie. De ha a VRM már a határon pörög (mondjuk éppen 48 TOPS teljesítményt kell kiszolgálnia), a maradék zaj "átüt" a processzormagokhoz. Ez a Transzfer hiba jelenség.
A VRM zaj „véletlen" bitmódosítóként működik. A CPU (FP64) esetében ennek nincs kockázati jelentősége: ha a VRM zaja miatt egy bit „megremeg", és egy pici feszültségtüske miatt egy érték megváltozik a 64-ből a 60. biten, az eredményben csak egy jelentéktelen kerekítési hiba lesz. A rendszer stabil marad. Ez azért van, mert a VRM zaja jellemzően kis amplitúdójú, és így általában csak az alacsony helyiértékű biteket (LSB) billenti át. Ha a zajszint tartósan megnő, a magas helyiértékű bitek (MSB) is érintettek lehetnek. A memóriában keletkező bit-hibákat szerverkörnyezetben az ECC memória ellensúlyozza, de a VRM zaj okozta számítási hibák a processzoron belül keletkeznek, ezekre az ECC nem nyújt védelmet, consumer gépeknél pedig jellemzően ECC „védelem” sincs.
Az NPU (INT8) esetében viszont nincs "biztonsági tartalék". Ha a 8 bitből akár csak egy is átbillen a zaj miatt, az az adott számértéket drasztikusan (akár 50-100%-kal) megváltoztathatja. Az AI-műveletek (mátrixszorzás) során ezek az értékek egymásra rakódnak, egyetlen zajos VRM-fázis miatt a végeredmény teljesen "elszállhat".
Az NPU-k rendkívül alacsony feszültségen üzemelnek a hatékonyság miatt. A hasznos jel így nagyon közel kerül (minél kisebb az üzemi feszültség, annál közelebb) a háttérzajhoz. Így ha a VRM nem tiszta áramot ad, a zaj belekerül a számítási ciklusba. Mivel az NPU eközben brutális sebességgel (TOPS) darálja a mátrixokat, a hiba végiggyűrűzik a hálózaton (error propagation). Ezért egy apró, feszültségingadozás okozta számítási hiba az első rétegben a tizedik rétegre már egy teljesen fals "hallucinációt" vagy szoftveres összeomlást (például egy irreális valószínűségi értéket) eredményez. Olyan ez az NPU számára, mintha egy zseniális matematikusnak egy lüktető technoparti közepén kellene integrálnia: meg tudja csinálni, de sokkal nagyobb az esélye, hogy elvét egy tizedest a zaj miatt.
Ha a rossz minőségű áramellátás gyakori, az NPU pontatlanná válik, a szoftver pedig elkezdi kompenzálni a hibát, ami még több hallucinációhoz vagy lassuláshoz vezet.
Összegezve: A modern AI-alaplapokon a VRM-szekció nem csak azért fontos, hogy ne melegedjen túl a proci, hanem azért is, mert közvetlen hatással van az intelligencia "élességére". Itt a tiszta áram már a kognitív pontosságról (is) szól, nem csak a stabilitásról.
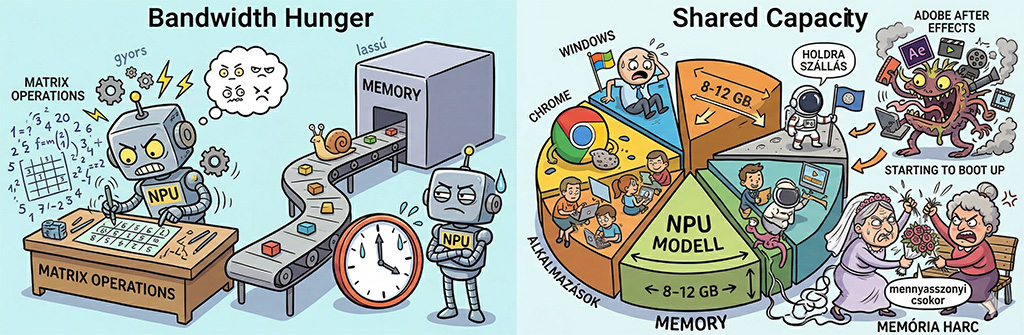
B.) A memória, mint kritikus keresztmetszet
Az NPU-nak nincs saját VRAM-ja, a rendszermemóriát használja (Unified Memory), ellenben sávszélesség kell neki.
- Minimum: 6000 MT/s (EXPO/XMP támogatással).
- Optimális: 6400 – 7200 MT/s, Dual-Channel vagy Quad-Channel kiosztással.
A lassabb RAM közvetlenül lassítja a válaszidőt (token/sec), egyetlen modullal pedig feleződik a sávszélesség, ami gyakorlatilag megfojtja az AI-t.
Frekvencia-szinkron és késleltetés: A SoC nem igényli a RAM frekvencia-szinkronját, mert a SoC belső órajele és a RAM órajele között mindig van egy osztó/szorzó egység (Memory Controller Ratio). Sokkal inkább azt az elérhető maximális sávszélességet kívánja, amit a memóriavezérlő még stabilan kezel. A QVL (Qualified Vendor List) ellenőrzés kulcspont, mert a SoC memóriavezérlője igen válogatós. Ha a modul nem szerepel a listán, nagyobb terhelés alatt könnyen válhat olyan instabillá a helyzet, mintha finomfőzeléket kapott volna ebédre az oviban. A késleltetés (CL) szintén nem kritikus pont: AI-műveleteknél a sávszélesség fontosabb, mint a szigorú időzítés, de a túl magas CL érték lassítja a válaszreakciót.
C.) Jelintegritás, a PCB rétegszám és az Interconnect
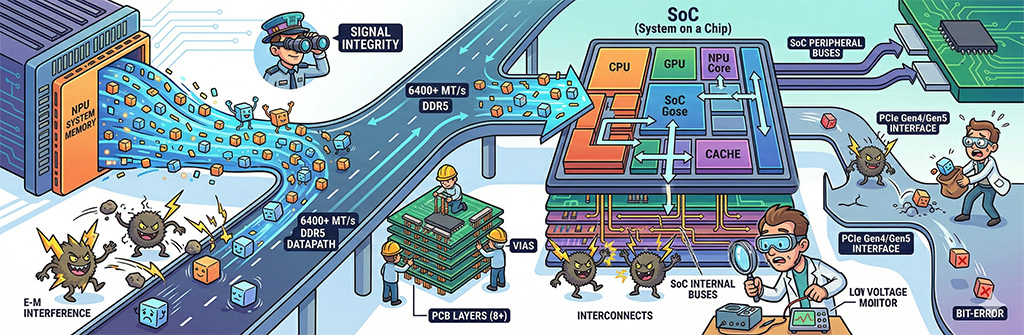 Az NPU hatalmas adatmennyiséget mozgat meg a rendszermemória és a SoC között, illetve a SoC-on belül is. A 6400+ MT/s sebességű DDR5 adatútvonalai rendkívül érzékenyek az elektromágneses interferenciára. Az adatvonalak (pl. a PCIe Gen4/Gen5 vagy az SoC-n belüli buszok) olyan alacsony feszültségen és olyan magas frekvencián mozognak, hogy egy apró interferencia is bit-hibát okozhat.
Az NPU hatalmas adatmennyiséget mozgat meg a rendszermemória és a SoC között, illetve a SoC-on belül is. A 6400+ MT/s sebességű DDR5 adatútvonalai rendkívül érzékenyek az elektromágneses interferenciára. Az adatvonalak (pl. a PCIe Gen4/Gen5 vagy az SoC-n belüli buszok) olyan alacsony feszültségen és olyan magas frekvencián mozognak, hogy egy apró interferencia is bit-hibát okozhat.
Ezért az alaplapi trace-eknek (huzalozásnak) tökéletesnek kell lenniük, emellett megfelelő rétegszámú PCB-re van szükség (minél több a réteg, annál jobb az árnyékolás), ami minimalizálja az interferenciát a memória és a SoC között. Enélkül az AI-modellek betöltése és futtatása során adatkorrupció léphet fel.
A chiplet-alapú felépítésnél a Data Flow Fabric / Interconnect belső adatkapcsolat felel azért, hogy a különböző motorok (CPU, GPU, NPU) közötti adatcsere ne váljon szűk keresztmetszetté a heterogén számítások során. Ez a „sztráda” a SoC-on belül.
D.) A tápellátás (PSU) „atombiztossága”
Az NPU hirtelen terhelésugrásai hatalmas tüskéket (Power Excursion) okoznak. A tápegységeknek bírniuk kell a névleges teljesítményük akár 200%-át is mikroszekundumokra. Ezt az ATX 3.0/3.1 szabvány szerinti PSU biztosítja anélkül, hogy leoldana a védelem. A magas hatásfokú (80 PLUS Gold/Platinum) tápegységek emellett jellemzően jobb belső kondenzátorokkal és alacsonyabb ripple-lel rendelkeznek, ami az NPU számítási pontosságához szintén kritikus. Egy hullámzó, zajos tápfeszültség nemcsak instabilitást okoz, hanem rontja az NPU számítási pontosságát is. (Zárójelben hoznám a párhuzamot a szünetmentes eszközök latency nélküli, tiszta szinuszával: pontosan ezért van ennek jelentősége, különösen szerveres/adatközpontos környezetben.) Emellett az alaplapi EPS csatlakozók minősége is felértékelődött a SoC stabil 1.0V-os szintjének fenntartásához.
E.) Hűtés: Active Cooling & Vapor Chamber
A heterogén terhelés kiszámíthatatlan hőgócokat hoz létre. Ehhez a hagyományos rézcsöves hűtés gyakran kevés. A Vapor Chamber (párakamrás) megoldás azért előnyös, mert sokkal gyorsabban és egyenletesebben teríti szét a hőt a hűtőborda teljes felületén, megakadályozva a lokális túlmelegedést, ami az órajelek visszavételéhez (thermal throttling) és a teljesítmény visszaeséséhez (esetleg adatkorrupcióhoz) vezetne.
F.) BIOS / UEFI "NPU Toggle"
A BIOS-ban dedikáltan kezelhető kell, hogy legyen az NPU erőforrás-kiosztása. Az alaplapi firmware nélkül az operációs rendszer meg sem látja az egységet, tehát elvárás az olyan BIOS, amely képes lefoglalni az erőforrásokat az NPU számára, és támogatja az összetett energiagazdálkodási profilokat.
5. A memória-dilemma: MoP vs. Diszkrét DDR5
Ebben a fejezetben érünk el az első generációs modern architektúrák legfájóbb kompromisszumához: a bővíthetőség és a sebesség közötti kényszerű választáshoz. Ahogy az korábban már kiderült, az NPU „élete” a sávszélességen múlik. A mérnököknek tehát el kellett dönteniük, hova tegyék a RAM-ot, hogy az AI ne „fulladjon meg”.
5.1. MoP (Memory on Package) – A notebookok útja
A mobilvilág (Apple M-széria, Snapdragon X Elite, Intel Lunar Lake) egy radikális megoldást választott: a memóriát közvetlenül a SoC tokozására forrasztják. Ezt hívjuk MoP-nak.
- Az előny: A fizikai távolság a memóriavezérlő és a chipek között szinte megszűnik. Nincs szükség hosszú alaplapi trace-ekre, így drasztikusan csökken a késleltetés és a fogyasztás. Ez az Apple-féle Unified Memory titka: az NPU, a GPU és a CPU egyazon „tányérból” eszik, méghozzá elképesztő sebességgel.
- A hátrány: Amit megveszel, azzal avulsz el. Nincs későbbi bővítés, nincs több RAM bepattintása. Ha 16 GB-tal kérted, de az LLM-ednek 32 kellene, vehetsz új gépet.
5.2. Diszkrét DDR5 (DIMM/SO-DIMM) – A PC-k szabadsága
Az asztali munkaállomások (és a hagyományosabb laptopok) megmaradtak a moduláris felépítésnél. Itt a memória külön foglalatokba (slotokba) kerül.
- Az előny: A rugalmasság. Ha ma 32 GB kell, holnap pedig 64 GB, csak cseréled a modulokat. Az AI-modellek mérete (paraméterszáma) folyamatosan nő, így a bővíthetőség itt komoly fegyvertény.
- A kihívás: Itt jön képbe az előzőekben említett jelintegritás. Mivel a RAM fizikailag távolabb van a SoC-tól, az adatoknak át kell verekedniük magukat az alaplapi huzalozáson. Itt dől el, miért kötelező a 8 rétegű PCB és a 6400+ MT/s sebességű modul: a moduláris felépítésből adódó fizikai hátrányt nyers sávszélességgel és kiváló minőségű alaplapi infrastruktúrával kell kompenzálni.
5.3. Miért „fáj” ez az NPU-nak?
Míg egy videójátéknál a 16 GB RAM és a 4800 MT/s sebesség is „elmegy”, egy lokális nyelvi modellnél ez a legszűkebb keresztmetszet.
- Sávszélesség-éhség: Az NPU másodpercenként több milliárd mátrixműveletet végez. Ha a memória lassú, az NPU tétlenül vár az adatokra.
- Shared Capacity: Azzal kell számolnunk, hogy a normál esetben combos 32 GB itt kevésnek is bizonyulhat. Kalkuláljuk bele, hogy ezen osztozik a processzoron kívül a Windows, a Chrome és a futó alkalmazások is. Ha az NPU lefoglal 8-12 GB-ot a modellnek, a Holdra szállás még talán beleférhet, de egy Adobe After Effects-et már meg se próbáljunk elindítani rajta, mert úgy összevesznek a memória használaton, mint aggszűzek az elhajított mennyasszonyi csokron.
A laptop és a PC vonal közötti alapvető logikai különbségek
| Paraméter | Laptop (Integrált / SoC) | Asztali PC (Moduláris) |
| Memória elhelyezkedése | MoP (Memory on Package): Közvetlenül a chip tokján belül. | DIMM (Slot): Az alaplapon, külön modulokban. |
| Sávszélesség | Kiemelkedő: Rövid utak, minimális késleltetés (latency). | Változó: Az alaplap (PCB) és a RAM minőségétől függ. |
| Skálázhatóság | Nulla: Amit megvettünk, az fix marad. | Magas: Utólag bővíthető több/gyorsabb RAM-mal. |
| Hűtési kihívás | A SoC-nak a RAM hőjét is el kell vezetnie. | A RAM hűtése passzív vagy az alaplapi légáram biztosítja. |
| NPU hatékonyság | Az egységesebb architektúra miatt gyorsabb válaszidő. | A moduláris felépítés miatt rugalmasabb modellkezelés. |
Összegezve: A notebookoknál az integráció (MoP) miatt kapunk egy villámgyors, de zárt rendszert. A PC-nél miénk a szabadság, de a stabilitáshoz és a sebességhez prémium alaplap és high-end RAM-modulok kellenek. Egyelőre nincs középút, csak kompromisszum: vagy a fizika dolgozik nekünk (MoP), vagy mi dolgozunk meg a fizikáért, mert a prémium alkatrészek ára még mindig a csillagos egekben van.
EZ A CIKK: I. rész: A CHIPEK FORRRADALMA >>>>>>
Az AI hatása az architektúrára, UMA és parcellázott SoC megjelenése, NPU kihívás, Interconnect, tiles, Szent Háromság: CPU-NPU-GPU, Adatformátumok: FP64/32 és FP16/INT8/4 szerepe, Kvantálás, Infrastruktúra követelmények, VRM és PSU, Memória és PCB szám, Hűtés, BIOS, Specifikus eltérések: MoP és diszkrét DDR5 (DIMM)
FOLYTATÁS: A CHIPEK FORRRADALMA: II. rész >>>>>>
Gyártói architektúrák: Intel vs. Qualcomm evolúció, Chiplet iskola, Forevos váz, Monilitikus die, modern SoC felépítése és anatómiája, Funkciók, SoC Layout, NPU csak AI kellék?
TRANSPARENCY DISCLOSURE – AI Act compliance
Ez a tartalom a mesterséges intelligencia etikus és transzparens támogatásával készült, az EU AI Act irányelveivel összhangban:
Szerző és szerkesztő: Szabó Roxána © 5N Kft
AI-támogatás:
▸ Háttér információk, anyaggyűjtés, tanácsadás: Gemini (Google LLC)
▸ Tartalmi és stilisztikai ellenőrzés: Claude AI (Anthropic)
▸ Képgenerálás: Gemini 3 Flash (Google LLC)
